2016/09/15(木)H8/3069F ROMライタの制作(2)
2017/10/12 19:41
基板がやっとできた。今回はこの工程は上手くできました。
この後、穴あけと部品付けを行います。

2016/09/09(金)H8/3069F ROMライタの制作
2017/10/12 19:39
その部品たちの一部が以下:

来週半ば目途に完成させないとならないという、半ば突貫工程です。。
と言っても、プリント基板さえ作ってしまえば、1~2日程度で出来そうな規模ですが。。
2016/08/16(火)BCD ⇔ 符号なしバイナリ変換
2017/10/12 19:38
毎回調べ直すという非効率なアホ作業をしでかしているので、自分メモ的にまとめてみようと・・orz
BCD コードというのは Binary Coded Decimal の頭文字で、日本語の古い文献などには「二進化十進数」とも表記されます。
数字を表示する機器などには未だ広く使われているようです。
BCDコードとバイナリコードの相違が理解できない方は、まずそれを他所で理解してください。理解できていないと、以下の記事の内容は全く理解できないでしょう。
今般の制作ボードの中にBCDコードを要求するLSIがあり、BCDコードとバイナリコードの相互変換が必要です。必要なのは 0~99の値なので、それに特化しています。
難しいのは、バイナリ → BCD変換のほうで、実に力ずくのアルゴリズムから、難解なものまでいろいろな方法があるのですが、応用が利くのは以下の、
『BCD部分の各桁について、「値が5以上ならば3を加算する」』
を基本にする手法。
以下を参考にしています:
http://www.geocities.jp/leitz_house/electronics/pic/bcd_01.htm
http://minkara.carview.co.jp/userid/526128/blog/24236882/
〔覚え書き:2進数 ⇒ BCD変換について…〕
オリジナルは、どうやらキャッシュしか残っていないようで、いつ消えるか判りません。
こんな方法で本当に出来るのか? という疑問を持たれる方が大半と察しますが、数学的見地でも本当に出来るのですから、科学の基礎というのは奥が深いです。
実際にC言語にて作ったものが以下(ビックエンディアン環境にて動作確認済):
/** cnv_byte_to_bcd 1バイトバイナリデータを1バイトBCDに変換 */
unsigned char cnv_byte_to_bcd(unsigned char bval) {
union {
struct {
unsigned char bcd ; // 変換後の値
unsigned char hex ; // 変換対象バイナリ
} conv ;
unsigned short buf ;
} convbcd ;
unsigned char bitcnt ;
if (bval >= 100) return (bval) ; // バイナリ値 100 以上は BCD に変換不可のため、そのままリターン。
convbcd.buf = 0 ; // 使用領域は予めゼロクリアしておく。
convbcd.conv.hex = bval ; // 変換対象のバイナリ値を置数。
for (bitcnt = 0 ; bitcnt < 8 ; bitcnt++) {
if (((convbcd.conv.bcd & 0x0f) + 0x03) >= 0x08) convbcd.conv.bcd += 0x03 ;
if (((convbcd.conv.bcd & 0xf0) + 0x30) >= 0x80) convbcd.conv.bcd += 0x30 ;
convbcd.buf <<= 1 ;
}
return convbcd.conv.bcd ;
}
肝になる部分は、union 共用体の部分で、メンバ bcd と メンバ hex の順番は重要です。対象ターゲットCPUは、ビックエンディアンで、その環境で動作確認しています。
インテルやAMDのCPUだと、殆どがリトルエンディアンなので、メンバ bcd と メンバ hex の定義を逆にしないと駄目かもしれません。
一方で、BCD → バイナリ変換は簡単です。4ビットごとに区切り、上位4ビットの値を×10し、下位4ビットをそのまま加算すると変換完了です。
/** cnv_bcd_to_byte 1バイトBCDデータを1バイトバイナリに変換 */
unsigned char cnv_bcd_to_byte(unsigned char bval) {
unsigned char convbin ;
convbin = ((bval & 0xf0) >> 4) * 10 + (bval & 0x0f) ;
return convbin ;
}
2016/08/10(水)新たな制御ボードの制作/開発作業
2017/10/12 19:37
左側が従来のもの、右側が自作したもの。
どういう道具かというと、制作/開発ターゲットになる制御基板に搭載するプログラム(これをファームウェアと言います)をパソコンから転送したり、起動・停止制御したりする道具です。


このように接続し、埋め込むプログラムを制作していきます。
制御基板の企画やハードウェア設計から当方が手掛け、ある程度設計を終えていたので、1カ月で終われるといいのですが、無理っぽいです。。orz
ちなみに、市販はしていませんし、今のところ市販の予定はありません。
NTTで光回線ルータをレンタルするのと似たような感じです。
(話だけはありますが、どう商品化するのか・・・が問題ですね)

2016/06/02(木)ソフトウェア的なデバッグでは判らない不具合・・・
2017/10/12 19:26
何度チェックしてもコンピュータプログラム的には間違いがない。
だが、意図した動作にならない。
今回はディジタル信号で計測温度を取得する温度センサで、温度センサとやりとりする信号線の波形を観ないと原因が判らない。
こんなときはオシロスコープを使うのですが、どんなに安価なものでも20万円程度はする高価な測定機器で、業務上必要なのにもかかわらず、筆者の手元には未だに無いのです。
ほんと、腹立だしいのと情けないのと交錯する心境です。
ですが、使い古しのデジタルオシロスコープセットを貸してくれた同業者が居られたので、折角ですから、問題は既にハードウェア設計変更で解決してしまったのですが、原因を追ってみました。
具体的な機種名は一応伏せておきますが、15年くらい前にノート型パソコンとセットで発売された機種のようで、帯域10MHz、サンプリング周波数 100MHz のようです。
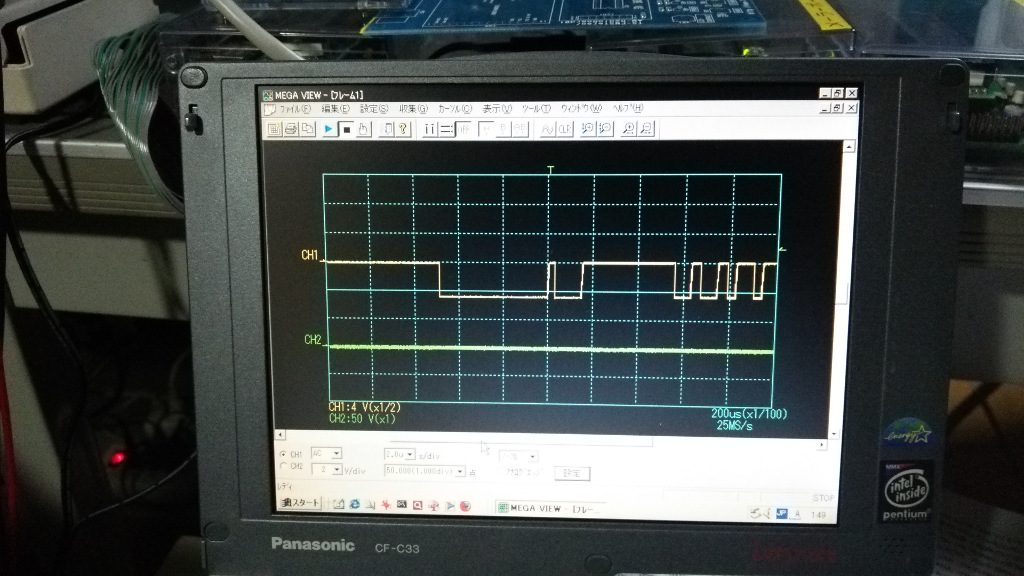
波形が取れたら、原因はすぐわかりました。
「この温度センサーとこのハードウェアは直結できない」です。
具体的な話は専門分野な方々にしかわからない話になるので、コメントで質問していただければ、回答致します(^^)
やっぱり欲しいねぇ。。オシロスコープ。。。
今、手元にあるオシロスコープは返却しないといけませんからね。
今般の案件では問題ないけれど、無線周波数帯には使えないし、、
2016/05/08(日)今更ながら DIGEST-MD5 SMTP認証[RFC2831,RFC1321]/postfix 3.0.3 + dovecot 2.2.21
2017/10/12 19:24
DIGEST-MD5 は、実装難易度などからサーバ側でのサポート割合が低いのですが、昨年からの POP before SMTP のサポート淘汰に伴い、この状況は変化しているようです。
DIGEST認証は、RFC2831 にて、従前から先行して使われていた HTTP における DIGEST認証と互換を持たせる形で規定されています。
日本語でのまともな資料がなく、仕様そのものも少し中途半端な感があります。
よって、CRAM-MD5 と異なり、サーバ側の動作環境で挙動が異なる場合が考えられるので、ここでは当方の環境である Postfix 3.0.3 + dovecot 2.2.21 における環境であることを明示しておきます。
〔2016/05/09 追記〕 Postfix 3.1.0 + dovecot 2.2.24 でも大丈夫でした。
DIGEST-MD5 によるSMTP認証は、以下のようなシーケンスを取ります。

[Client -> Server] AUTH DIGEST-MD5 [Server -> Client] 334 cmVhbG09ImV4YW1wbG...《以降省略》 [Client -> Server] dXNlcm5hbWU9ImluZm8uZXhhbXBsZS5jb20i...《以降省略》 [Server -> Client] 334 cnNwYXV0aD1mOTE2MGE0NzQ4MjE3MmNlMmMxNDk2NGFjZTUyN2VjOA== [Client -> Server] ZjkxNjBhNDc0ODIxNzJjZTJjMTQ5NjRhY2U1MjdlYzg= [Server -> Client] 235 Authentication successful.認証途上でサーバとやりとりするデータは、必ず Base64エンコードして送受信します。
クライアント側では、Base64 デコードして処理しなければなりません。
DIGEST-MD5 における処理の要(かなめ)は、後述するレスポンス MD5 ハッシュの生成になります。
この部分はちょっと複雑です。
(対応した案件でもC言語のソースコードレベルで 150行前後の規模になってしまった)
順に処理を追ってみます。
1)サーバに対し、AUTH DIGEST-MD5 コマンドを発行すると、状態コード 334 で、Base64エンコードされた文字列が返される。先ずはこれをデコードする。
・図中のBase64文字列をデコードすると、下記の文字列が得られます。これを「チャレンジ」と言います。
realm="example.com",nonce="JQMKtdgbEhMra4GdAYmAjQ==",qop="auth",charset="utf-8", algorithm="md5-sess"・これらは、パラメータとその値です。
表示都合上、改行入れていますが、実際には改行しません。
・ダブルクォーテーションで括ってある文字列については、ダブルクォーテーションを除去します。
・DIGEST-MD5 SMTP 認証の場合、qop="auth" と algorithm="md5-sess" になるので、ここではこの事例のみを扱います。
・認証フェーズで使用する文字コードは、通常 utf-8 です。
このパラメータが無い場合は、iso-8859-1 と見なさなければなりません。
しかし、通常の 7bit ASCII を使う限り、utf-8 と 7bit ASCII は同じで、文字コードとして 0x20 ~ 0x7e の間しか出てこないので全く意識していません。
2)レスポンス MD5ハッシュの生成
2-1) RFC2831 で規定する A1 データ列を生成。
RFC2831 では A1 データ列は以下のように規定されています。
A1 = { H( { username-value, ":", realm-value, ":", passwd } ),
":", nonce-value, ":", cnonce-value, ":", authzid-value }
ここで、
username-value = info.example.com (ユーザ名を平文で)
realm-value = サーバから与えられた realm の値を複写 (example.com)
passwd = userpassword (パスワードを平文で)
nonce-value = サーバから与えられた nonce の値を複写(JQMKtdgbEhMra4GdAYmAjQ==)
cnonce-value = lWF{[QuiRj}_L[PW (クライアント側でランダム文字列を生成する)
authzid-value = サーバから与えられた authzid の値を複写
としますが、通常、authzid パラメータは与えられませんので、この場合はこうしろと規定されています。
A1 = { H( { username-value, ":", realm-value, ":", passwd } ),
":", nonce-value, ":", cnonce-value }
具体的には、まず username-value,realm-value,passwd を ':' で連結した文字列info.example.com:example.com:userpasswordに対して、MD5ハッシュを算出し、
(ハッシュ値は以下の16バイトデータになります)

この 16バイトデータと、nonce-value と cnonce-value を ':' で連結し、連結した文字列の MD5 ハッシュを算出しておきます。
算出値は
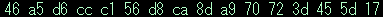
となります。
2-2) A2 データ列の生成
RFC2831 では A2 データ列は以下のように規定されています。
A2 = { "AUTHENTICATE:", digest-uri-value }
ここで、digest-uri-value は、サーバタイプ、ホスト名、サーバ名を '/' で連結した文字列で、サーバタイプは 'smtp'、ホスト名は DNS MXレコードで検索できるFQDN、サーバ名は通常省略します。ここで、ホスト名を 'mx.example.com' とすると A2 データ列は以下のようになります。
AUTHENTICATE:smtp/mx.example.comA2 データ列に関しても MD5ハッシュ値を算出しておきます。
算出値は

となります。
2-3) response ハッシュ値の算出
RFC2831 では以下のように規定されています。
HEX( KD ( HEX(H(A1)),
{ nonce-value, ":" nc-value, ":", cnonce-value, ":",
qop-value, ":", HEX(H(A2)) }))
KD は2つの文字列を':'で連結の意、HEX はバイトデータ列を 16進文字列表記に変換、
H は、ハッシュ関数の意味で、ここでは MD5 になります。
ここで示している具体例だと、先ず
46a5d6ccc156d8ca8da970723d455d17:JQMKtdgbEhMra4GdAYmAjQ==:00000001:
lWF{[QuiRj}_L[PW:auth:e7280b0554e7e6636bd6a32ec6d5d2cf
※ 表示上、改行しているが、実際は絶対に改行を入れないこと。のような連結文字列を生成し、この連結文字列に対して MD5ハッシュ値を16進数表記したものを得ます。
算出文字列は、
729303fe19230ab4d3733dd28ab2b0b2となります。
2-4) サーバに返すレスポンスデータ列の生成
具体的には以下のような文字列を生成します。
username="info.example.com",realm="example.com",nonce="JQMKtdgbEhMra4GdAYmAjQ==",
cnonce="lWF{[QuiRj}_L[PW",nc=00000001,qop=auth,digest-uri="smtp/mx.example.com",
response=729303fe19230ab4d3733dd28ab2b0b2,charset="utf-8"
※ 表示上、改行しているが、実際は絶対に改行を入れないこと。・qop パラメータにはダブルクォーテーションを付けないことに注意してください。
・realm パラメータ、nonce パラメータ、qop パラメータは、サーバから与えられた値をそのまま返します。
・realm 値は空文字列のことがあります。この場合もそのまま空文字列を返します。
ただ、RFC2831 では「サーバのホスト名が入る」とされています。
・時折、digest-uri パラメータのホスト名に realm の値を設定するような事例を見かけますが、これは正しくありません。DNS のMX レコードに指定されるホスト名を使用すべきと観ています。RFC2831 に説明はあるのですが 、今一つ明確ではありません。。
・nc 値は、事実上 00000001 固定です。サーバ側はこれをチェックしているため、00000001 以外の値だと認証エラーになります。
上記文字列を Base64 エンコードすると、シーケンス図の中に書いてある文字列になります。この Base64エンコード文字列をサーバに返信します。これを「レスポンス」と言います。
3)認証確認
DIGEST-MD5 はこれでユーザ認証処理完了ではなく、もう一度状態コード 334 で Base64 エンコードした文字列が送られてきます。
cnNwYXV0aD1mOTE2MGE0NzQ4MjE3MmNlMmMxNDk2NGFjZTUyN2VjOA==を Base64デコードすると、
rspauth=f9160a47482172ce2c14964ace527ec8が得られます。
この32バイト長の16進数文字列は、2)レスポンス MD5ハッシュの生成 で A2 データ列を
A2 = { ":", digest-uri-value }
に変えて処理したものになります。クライアント側は、肯定応答をするために同じように A2 データ列を上記のものに変更したレスポンスハッシュ値を算出し、サーバ側に送り返します。
このあたりは、RFC2831 に明確な記載がなく、当方の環境で確認した挙動です。
このレスポンスがあって、サーバは初めて状態コード 235 を返して認証フェーズを完了します。
2016/05/07(土)今更ながら CRAM-MD5 SMTP認証[RFC2195,RFC2104,RFC1321]
2017/10/12 19:21
電子メール送信の不正利用を減らす目的の一環として、送受信時に「認証」という手続きを踏むのですが、昨今では、この部分にかつての主流であった「POP before SMTP」という方式は昨年あたりから淘汰されつつあり、各種 の「SMTP 認証」という方式になってきています。
電子メールを送受信するだけの殆どの一般ユーザなら、電子メール送受信ソフト(MUA)の設定時以外は全く意識することは無いのですが、今般は電子メール送受信の機能そのものを実装するため、仕組みを理解しないことには話 になりません。
CRAM-MD5 方式による認証手順仕様は、POP3/IMAP4向けに策定された RFC2195 で規定されており、そこで使用される HMAC-MD5 方式による暗号化ハッシュでパスワードを検証する仕組みになっています。
考え方としては、クライアント側で提示した HMAC-MD5 ハッシュ値と、サーバ側でクライアント側と同じ手順で算出した HMAC-MD5 ハッシュ値が一致することで「パスワード一致」と見做すわけです。
ここでの暗号化ハッシュの要(かなめ)は MD5 と呼ばれる方式で、任意長のデータ列から「暗号化理論に基づくハッシュ関数」により16バイト(128bit長)のハッシュ値を作りだすもので、RFC1321 にて規定されています。
CRAM-MD5 によるSMTP認証は、以下のようなシーケンスを取ります。

[Client -> Server] AUTH CRAM-MD5 [Server -> Client] 334 PDIwMTYwNTA4MDE1NzMyLjQ2QTRFNENGRjUyMUBteDIuYmFzZWtlcm5lbC5uZS5qcD4= [Client -> Server] aW5mby5leGFtcGxlLmNvbSAxODBjYmQwNTdjNDQxOTFhYjRkOTU2NWQ3MzA2ZmVmZg== [Server -> Client] 235 Authentication successful.ここで、
PDIwMTYwNTA4MDE1NzMyLjQ2QTRFNENGRjUyMUBteDIuYmFzZWtlcm5lbC5uZS5qcD4=
という文字列は、
<20160508015732.46A4E4CFF521@mx2.basekernel.ne.jp>という文字列を Base64エンコードしたもので、クライアント側でデコードして使用します。
この文字列は 「チャレンジ」と言います。認証毎にランダムな文字列です。
クライアント側では、SMTPサーバを利用するユーザ名と当該ユーザパスワードを暗号化したものを Base64エンコードにて送り返します。これを「レスポンス」と言います。
ここで「ユーザパスワードの暗号化」を行うのですが、この部分が CRAM-MD5 方式の核となるところです。以下に生成手順を示します:
・CRAM-MD5 は「鍵付きハッシング」と呼ばれる暗号化を使用します。
これは、HMAC と言い、RFC2104 にて規定されています。
ハッシュ関数にMD5 を使うので、HMAC-MD5 と称します。
・RFC2104 によれば、HMAC の算出は、
H(K XOR opad, H(K XOR ipad, text))となっています。
H は、ハッシュ関数を意味し、ここでは MD5 です。他に SHA1 などあります。
K は、ここでは平文で示されたパスワードです。例示として userpassword を示します。
opad は、0x5c を64バイト並べた文字列、
ipad は、0x36 を64バイト並べた文字列、
text は、サーバから送られてきた「Base64エンコードされたチャレンジ文字列」をデコードしたものです。
・Phase0 もし、パスワード文字列が 64バイトを超える場合、その文字列の MD5ハッシュ値を算出し、そのハッシュ値16バイトデータ列を以降の処理でパスワード文字列として扱う。
・Phase1 パスワード文字列 'userpassword' と ipad のバイト単位 XOR 演算
[K XOR ipad]
以下のようになります。

・Phase2 パスワード文字列 'userpassword' と opad のバイト単位 XOR 演算
[K XOR opad]
以下のようになります。

・Phase3 Phase1 で算出した 64バイトデータ列と、サーバから得たチャレンジ文字列を連結し、16バイトの MD5 ハッシュ値を得る。
・Phase4 Phase2 で算出した 64バイトデータ列と、Phase3 で得た16バイトデータ列を連結し、16バイトのハッシュ値を得る。
・Phase5 Phase4 で得たハッシュ値を16進数文字列化する。
結果は、
180cbd057c44191ab4d9565d7306feffとなります。
・Phase6 認証対象のユーザ名と、Phase5 で得た32バイト長文字列を半角スペースで連結し、Base64 でエンコード。これをサーバへレスポンスとして送り返す。
Base64エンコード後の文字列は
aW5mby5leGFtcGxlLmNvbSAxODBjYmQwNTdjNDQxOTFhYjRkOTU2NWQ3MzA2ZmVmZg==となります。これは、
info.example.com 180cbd057c44191ab4d9565d7306feffを、そのまま Base64 エンコードしたものです。
パスワードを解析・解読可能な状態でインターネット上に送らないので、セキュリティ的には安全とされていましたが、昨今ではMD5ハッシュの脆弱性が指摘されているのと、CRAM-MD5 認証そのもので電子メール本文そのものが暗号化されるわけでは無いので、この点での脆弱性を指摘する意見があるようです。
ですが後者に関しては言及のレベルや話題の論点が全く異なる話であり、
「認証と通信そのものを混同してるよね」という印象しか個人的には持てません。
2016/02/16(火)H8/3069F 使用ボードの制作
2017/10/12 19:17

旧日立製作所の半導体部門(現在のルネサス・テクノロジ)が2001年ころに商品化したマイクロコンピュータチップを使って2~3点ほど制御ボードを作ることになりそうです。。
今年はこの仕事がメインになりそうな勢い。
調査だけで徹夜になってしまいました。
必要なものの調達は概ね終わり、制作にあたっての課題は見えていますが、未経験な内容もあり、ちょっと先が思いやられます...orz